
What agents and skills really are, and why natural language is the next abstraction layer in programming — written for engineers trying to make sense of the AI era without wading through official docs.
▸
about.md
I am a Research Scientist at Meta AI London. I work on video diffusion models, generative rendering, talking avatars, and world models — teaching machines to observe, imagine, and simulate visual reality. The longer-term hope is to make worlds as easy to build as they are to imagine — so anyone can freely express the ones in their head, not only engineers.
I received my Ph.D. in Computer Science from the University of Surrey, supervised by Prof. Tao Xiang and Prof. Yi-Zhe Song, and worked closely with Dr. Xiatian (Eddy) Zhu.
I completed my Bachelor's degree in Computer Science (Artificial Intelligence) at the University of Malaya, where I was a lab member of CISIP under Prof. Chan Chee Seng.
Contact: kamwoh [at] gmail.com
> Research Journey
2026 – ??? 🇬🇧 UK
Yume — A Programmable World Model
Building explicit world models you can actually program. Yume is a world engine on Godot where entire games are defined as JSON data rather than per-game code. A minimal deterministic interpreter with seven primitives (Entity, Tag, Rule, Trigger, Effect, Query, Relation) runs the world tick-by-tick, so you describe a world in plain language, Claude compiles it into JSON, and it materialises into something runnable — no world-specific engine code. The same substrate doubles as a testbed for RL and neural world-model training. Early prototypes below, all fully generated games.
joint video & camera generation
2026 🇬🇧 UK
Unifying Video Generation & Camera Pose
Kaleido learned to generate novel views given unseen camera poses — but can we also recover the camera trajectory from a video? The key challenge is that camera parameters live in a completely different space from pixels. Plücker embeddings are 6-channel — incompatible with pretrained 3-channel video VAEs, meaning you'd need to finetune just to fit the input format. Rays as Pixels solves this with raxels: each camera is "unfolded" into a 3-channel image where every pixel stores its ray origin + direction, so camera poses look just like RGB frames and go straight through the same VAE. Now both can be co-denoised together, and a single model handles pose estimation, trajectory-controlled generation, and joint video-camera synthesis.
LLMs as vector graphics generators
2026 🇬🇧 UK
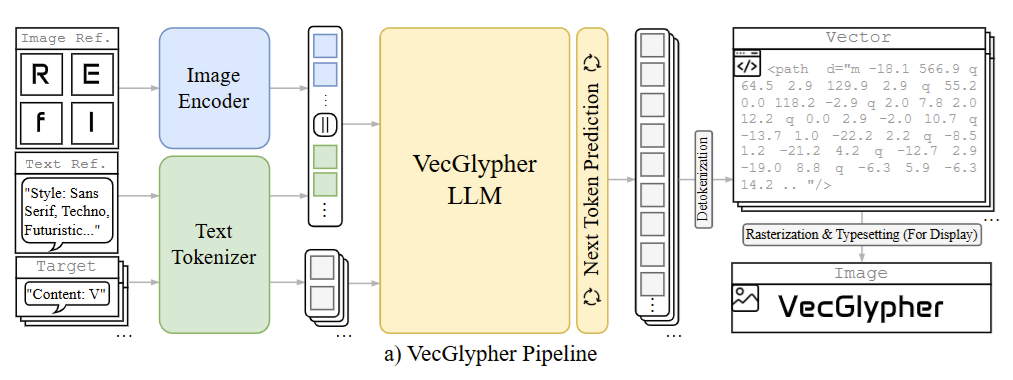
Training LMs for Vector Graphics
Applied structured spatial generation to a new modality. VecGlypher fine-tunes multimodal LLMs to directly emit SVG path commands — no raster intermediate — via a two-stage curriculum (syntax mastery, then style refinement), producing editable vector glyphs from text or image exemplars. If LLMs can reason about 2D geometry as text, the leap to 3D meshes is just one more dimension — today's models may already be closer to generating 3D worlds than we think.
novel view synthesis as generation
2025 – 2026 🇬🇧 UK
Generative Neural Rendering
Moved beyond per-object NeRF distillation toward a visual world model. Kaleido is a sequence-to-sequence transformer that directly synthesises novel views — no explicit 3D representations, no per-scene optimisation — pre-trained on video, learning to imagine how the world looks from any viewpoint. Along the way, picked up large-scale Blender rendering and 3D modeling — the undergrad game dev itch never really went away.
part-aware 3D from 2D images
2024 – 2025 🇬🇧 UK

Learning 3D from Unposed 2D
Returned to the 3D world that fascinated me since my undergrad game engine days — this time through neural rendering. Restudied classical rendering, NeRF, and implicit neural representations, then built Chirpy3D: fine-tuning multi-view diffusion models with LoRA, learning a continuous part latent space, and distilling part-controlled views into NeRF — generating fine-grained 3D objects from unposed 2D images alone.
compositional generation via attention
2024 🇬🇧 UK
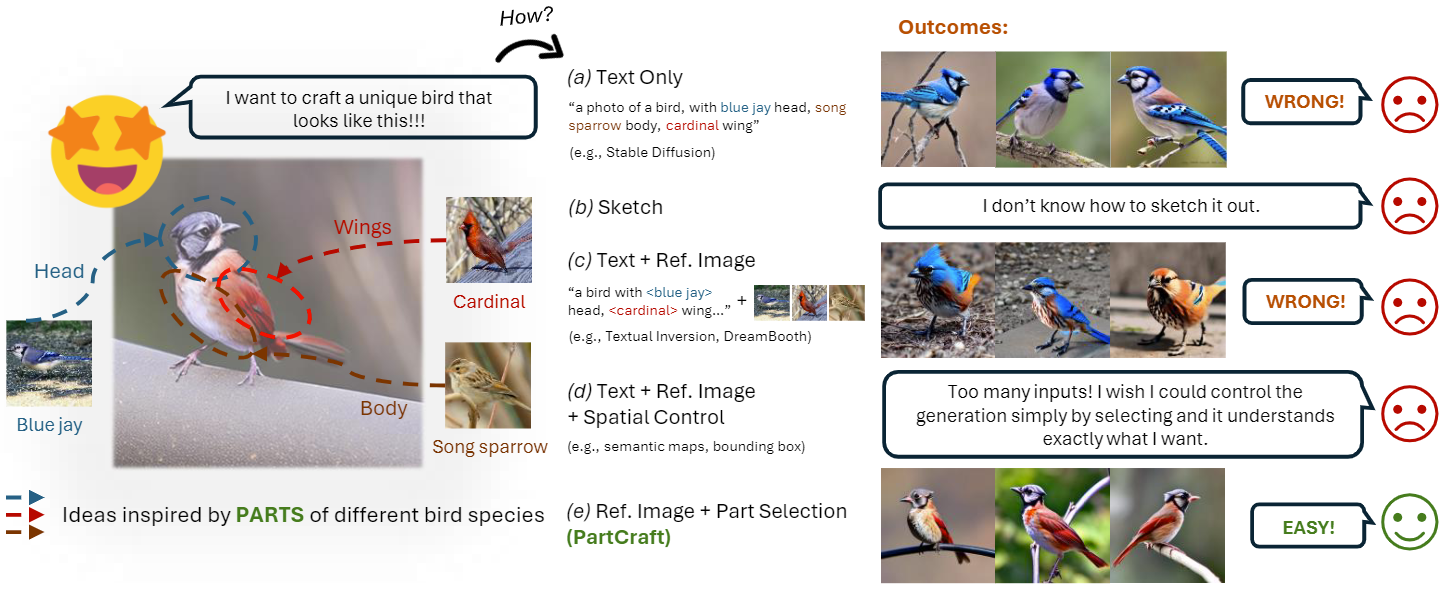
Controlling Diffusion Models
ConceptHash showed that parts can be encoded separately — but can we also generate by parts? PartCraft answers yes: entropy-based attention losses steer cross-attention so each part token controls its own spatial region, enabling compositional image generation from part-level descriptions.
hash bits as semantic concepts
2023 – 2024 🇬🇧 UK
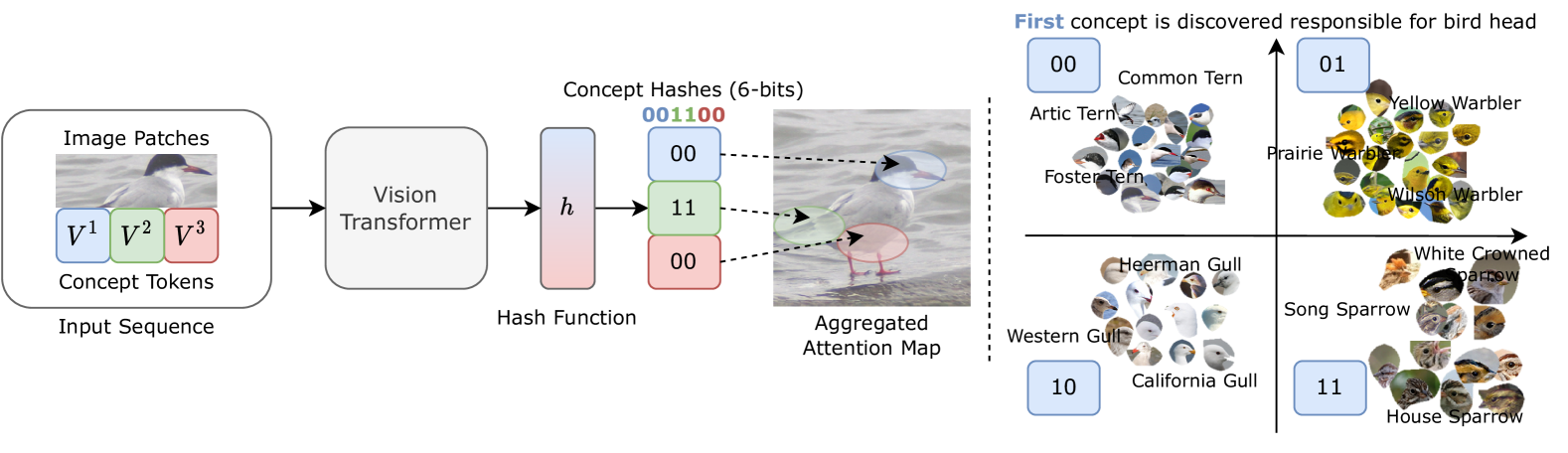
Interpretable Visual Hashing
ConceptHash made hash codes interpretable — each sub-code attends to a discoverable visual part, turning hash bits into semantic concepts. The first sign that compact representations could capture meaningful structure, not just similarity.
learning compact binary codes
2020 – 2023 🇨🇳 → 🇲🇾 → 🇬🇧
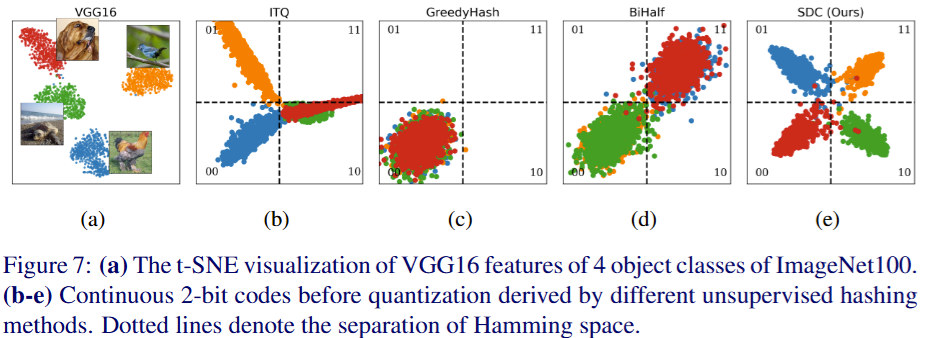
Deep Hashing for Image Retrieval
The orthogonal binary codes used in watermarking map directly to hashing — both need compact codes with maximum Hamming separation. DPN introduced central similarity with orthogonal class centres; OrthoHash distilled it to a single cosine objective; SDC solved similarity collapse via Wasserstein-calibrated distributions; and FIRe unified benchmarking across the field.
protecting generated outputs
2020 – 2022 🇨🇳 China
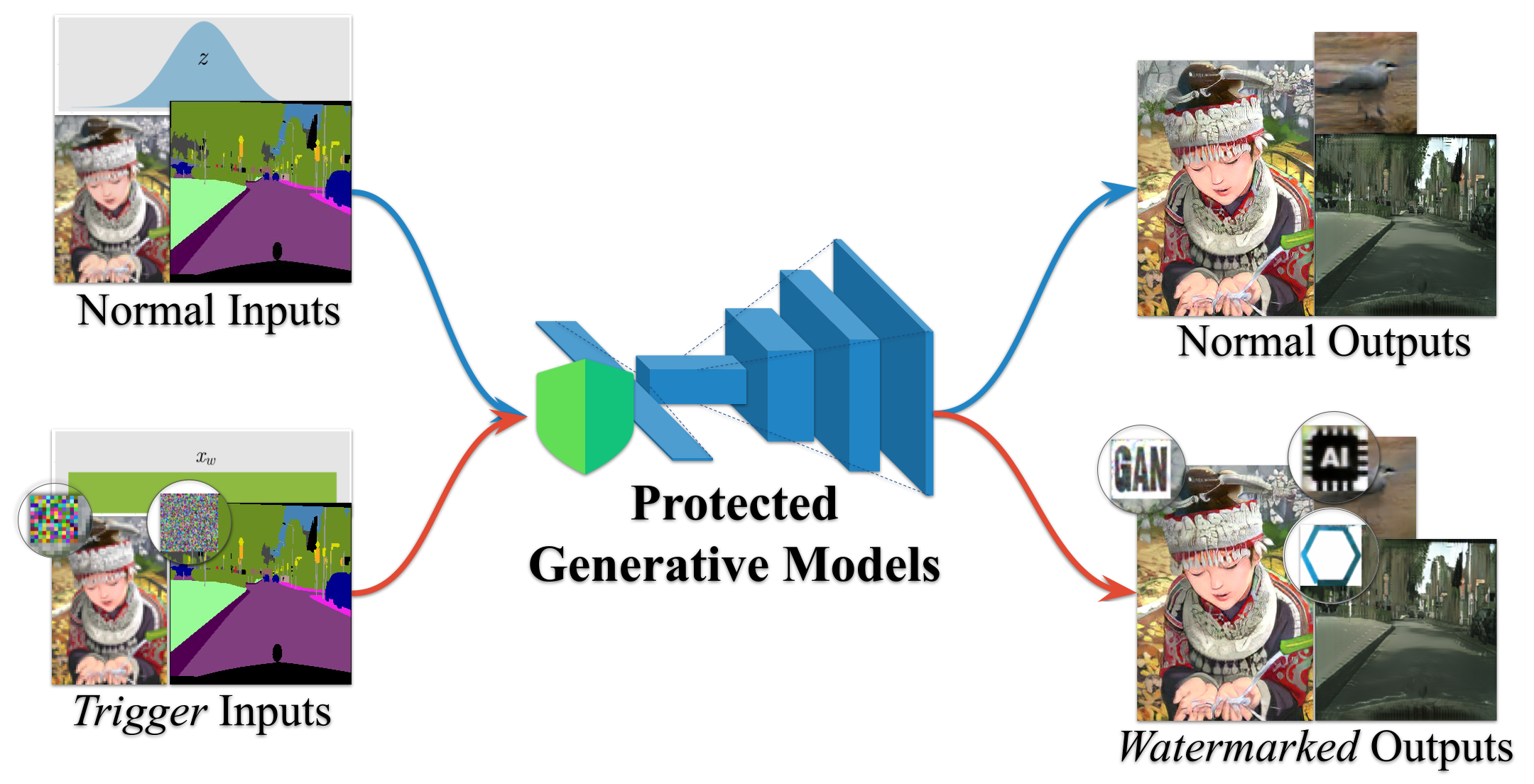
Watermarking DNN Outputs
Extended ownership protection from model weights to model outputs. IPR-GAN embeds both white-box signatures in GAN weights and black-box watermarks in generated images, enabling dual verification without sacrificing visual quality.
DNN intellectual property protection
2019 🇲🇾 Malaysia
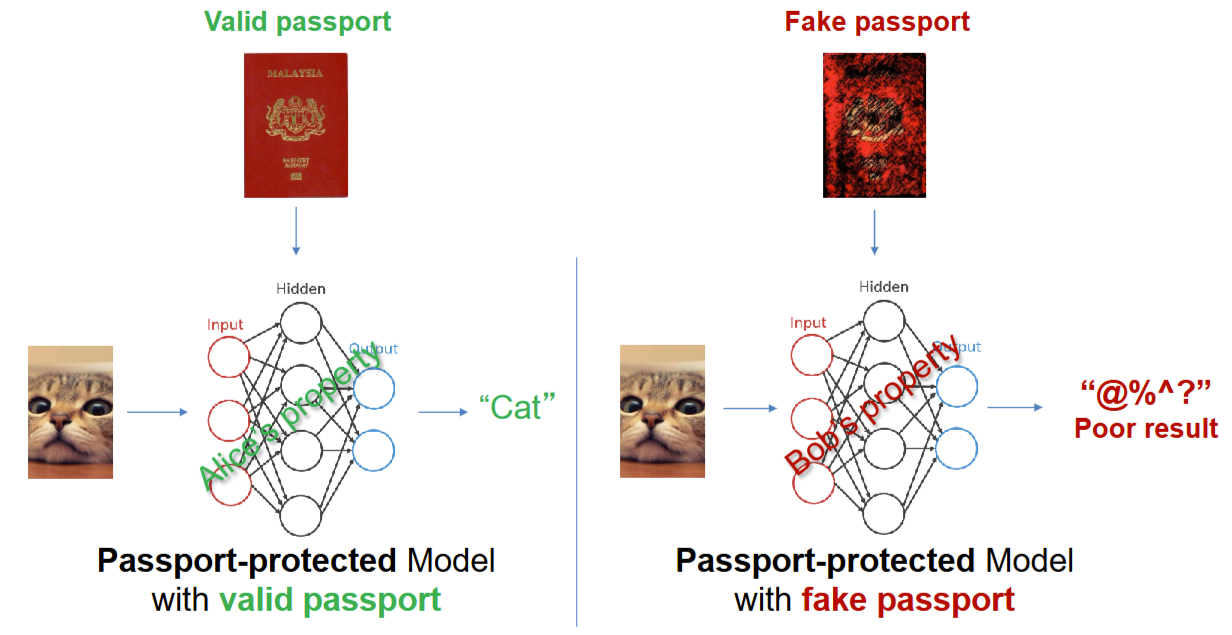
Watermarking DNN Weights
First major publication — studied how to protect DNN intellectual property. DeepIPR embeds learnable "passport" layers into normalization parameters — the model only produces correct outputs with the right passport, defeating ambiguity attacks without degrading performance.
visualising what networks learn
2018 – 2019 🇲🇾 Malaysia
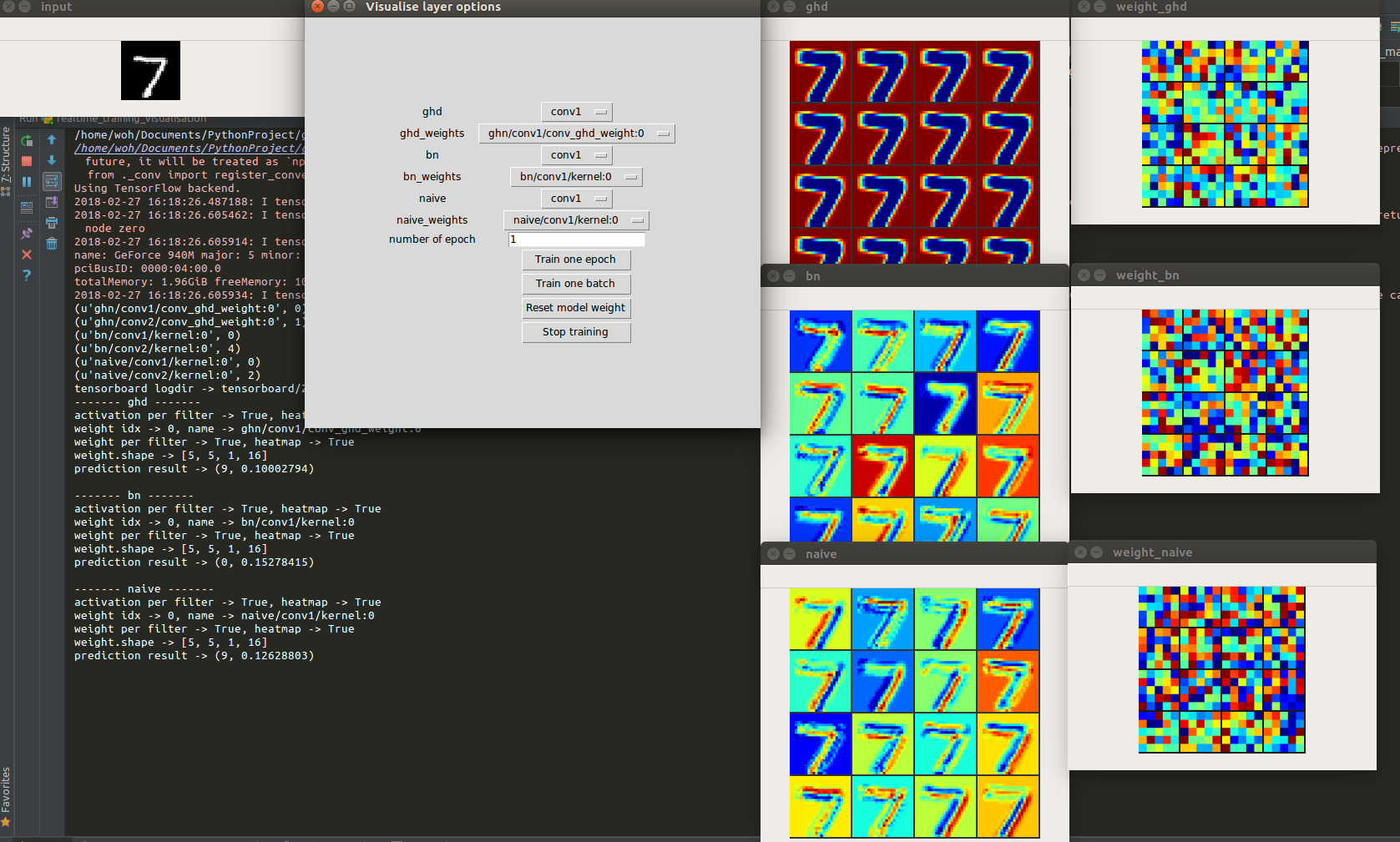
Understanding CNNs from the Inside
After training models to recognise and detect objects, wanted to understand what they actually learn. Studied CNN interpretability — visualising internal representations and asking how networks arrive at their decisions. Published first workshop paper at AAAI-19.
detecting and localising objects
2017 🇲🇾 Malaysia
Object Detection
Moved from recognition to detection — trained YOLO and SSD models to detect and localise cars. First taste of spatial reasoning: not just what is in the image, but where.
CNNs, game engines, and curiosity
2016 – 2018 🇲🇾 Malaysia
Where It All Started
Two parallel obsessions as an undergrad: training CNNs (car plate OCR with Caffe, back when deep learning meant writing prototxt files by hand) and building games (a Java-based game engine, an asteroid game with simple game AI, and hours studying how rendering and game engines work). No papers, no grand vision — just a curious student who wanted to make things that see and things you can play.
> Selected Publications
> Blog
A meta first post: how a static GitHub Pages site gets indexable blog posts without a backend.