🐦Chirpy3D: Part-Aware Multi-View Diffusion for Creative Fine-Grained Object Generation 🐦

- Kam Woh Ng1
- Jing Yang2
- Jia Wei Sii3
- Jiankang Deng4
- Chee Seng Chan3
- Yi-Zhe Song1
- Tao Xiang1
- Xiatian Zhu1
- University of Surrey1
- University of Cambridge2
- Universiti Malaya3
- Imperial College London4

Abstract
Understanding and generating the fine-grained structure of objects -- such as birds with species-specific beaks, wings, and tails -- is a long-standing challenge in computer vision. We propose Chirpy3D, a part-aware multi-view diffusion framework that learns a hierarchical part latent space from unposed 2D images, using only off-the-shelf 2D part segmentation masks as spatial guidance -- without requiring any 3D data, camera poses, or manual part annotations. This latent space enables intuitive part-level swapping, interpolation, and zero-shot composition. A self-supervised feature consistency loss further encourages structural alignment across views, allowing coherent generation even with hybrid or unseen part combinations. Our core contribution is the controllable part-aware latent space and multi-view diffusion model. Downstream 3D generation is supported via any differentiable renderer such as NeRF but is orthogonal to the main framework, making Chirpy3D a flexible foundation for creative object generation in the absence of structured 3D data.
Methodology
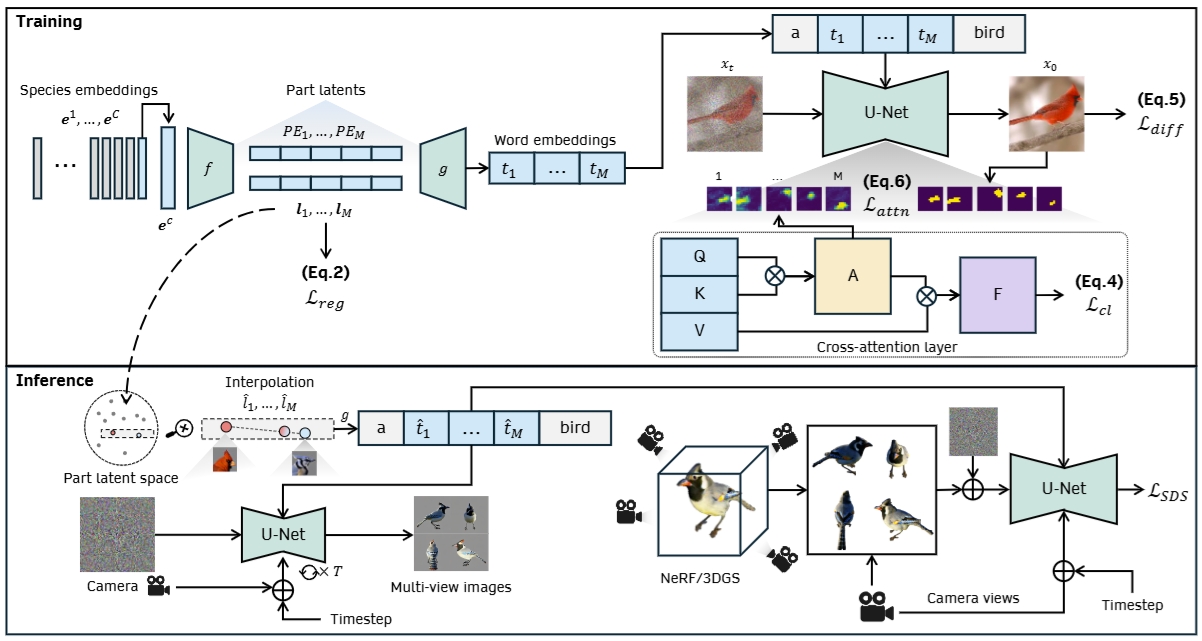
Overall architecture of our \( \textbf{Chirpy3D} \). \( \textbf{(Top)} \) During training, we fine-tune a text-to-multi-view diffusion model (e.g., MVDream) with only 2D images of birds. We aim to learn the underlying part information by modeling a continuous part-aware latent space. This is achieved by learning a set of species embeddings \( \mathbf{e} \), project them into part latents \( \mathbf{l} \) through learnable \( f \), decode into word embeddings \( \mathbf{t} \) through learnable \( g \) and insert into text prompt. We train the diffusion model with diffusion loss and multiple loss objectives -- \( \mathcal{L}_{\text{reg}} \) to model part latents as Gaussian distribution, \( \mathcal{L}_{\text{attn}} \) for part disentanglement, and our proposed \( \mathcal{L}_{\text{cl}} \) to enhance visual coherency. \( f \) and \( g \) are trainable modules. For efficient training, we added LoRA layers into cross-attention layers of the U-Net. \( \textbf{(Bottom)} \) During inference, we can first preview multi-view images by selecting desired part latents as condition before turning them into 3D representations (e.g., NeRF) through SDS loss \( \mathcal{L}_\text{SDS} \).
Multiview Generation
Not only we can generate multiview images of existing classes, we can also generate hybrid version of them (randomly interpolated for each part).














The following multiview images are generated by randomly sampled part latents.















3D Birds
3D generation usingthreestudio with random sampled part latents.
some examples from CUB200.
additional examples from PartImageNet and sims4-faces.
Citation
@misc{ng2024chirpy3d,
title={Chirpy3D: Part-Aware Multi-View Diffusion for Creative Fine-Grained Object Generation},
author={Kam Woh Ng and Jing Yang and Jia Wei Sii and Chee Seng Chan and Jian Kang Deng and Yi-Zhe Song and Tao Xiang and Xiatian Zhu},
year={2025},
eprint={2501.04144},
archivePrefix={arXiv},
primaryClass={cs.CV}
}